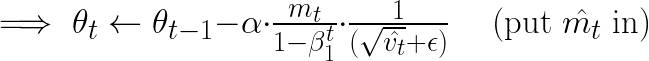When I reviewed the implementation of Adam optimizer in tensorflow yesterday, I noticed that it’s code is different from the formulas that I saw in Adam’s paper. In tensorflow’s formulas for Adam are:

But the algorithm in the paper is:

Then quickly I found these words in the document of tf.AdamOptimizer:
Note that since AdamOptimizer uses the formulation just before Section 2.1 of the Kingma and Ba paper rather than the formulation in Algorithm 1, the “epsilon” referred to here is “epsilon hat” in the paper.
And this time I did find the ‘Algo 2’ in the paper:

But how does ‘Algo 1’ tranform to ‘Algo 2’? Let me try to deduce them from ‘Algo 1’: