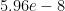Three weeks passed since the previous article. Here are the answers to the previous three questions:
Q1: The original paper of CLIP uses L2 normalization on multimodal embeddings. But in my test, the model will not converge with it.
Answer 1: The reason the model didn’t converge is that the learning rate is too large. After reducing the learning rate a bit and adding the L2 normalization, the model could get above 80% validation accuracy. The L2 normalization essentially projects embeddings to a high-dimensional sphere with a one-unit radius, which by intuitive could regularize the model.
Q2: Adding the learnable temperature parameter will cause a training error, which requires a “retain_graph=True” argument for “backward()”
Answer 2: If I use the code
def __init__(self):
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07)).exp()
def forward(self):
...
logits_per_image = self.logit_scale * img_embds @ txt_embds.T
it will report the error
Traceback (most recent call last):
File "/home/robin/code/try_multimodal/train.py", line 196, in <module>
trainer.train(args)
File "/home/robin/code/try_multimodal/train.py", line 149, in train
train_result = self.train_loop(cmodel, optimizer)
File "/home/robin/code/try_multimodal/train.py", line 81, in train_loop
self.scaler.scale(loss).backward()
File "/home/robin/miniconda3/envs/nanoGPT/lib/python3.10/site-packages/torch/_tensor.py", line 522, in backward
torch.autograd.backward(
File "/home/robin/miniconda3/envs/nanoGPT/lib/python3.10/site-packages/torch/autograd/__init__.py", line 266, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
RuntimeError: Trying to backward through the graph a second time (or directly access saved tensors after they have already been freed). Saved intermediate values of the graph are freed when you call .backward() or autograd.grad(). Specify retain_graph=True if you need to backward through the graph a second time or if you need to access saved tensors after calling backward.But if I moved the “exp()” to “forward()”:
def __init__(self):
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
def forward(self):
...
logits_per_image = self.logit_scale.exp() * img_embds @ txt_embds.T
It works well. The reason is that “exp()” would bring the gradient to “logit_scale” so we’d better to let it in “forward()” to avoid graph edge duplication.
Q3: When using “torch.compile()”, it will report a Triton error after the first epoch
Answer 3: Seems the “torch.compile()” needs the input batch to be fixed shape, which means you’d better not change the batch_size at the training step. To avoid this, I dropped the last batch of the dataset since the last batch usually wouldn’t have enough samples for BATCH_SIZE.
There is a new discovery for “torch.compile()”. Yesterday I was trying to compile the model (a self-implement ALBEF) but came an error:
...
torch._dynamo.exc.BackendCompilerFailed: backend='inductor' raised:
InvalidCxxCompiler: No working C++ compiler found in torch._inductor.config.cpp.cxx: (None, 'g++')
After tumbling in the debug document of PyTorch compiling, I finally found out that the solution is just installed “g++” on my computer…
Previously, the evaluation of 50000 val images of ImageNet1K shows that the top-5 accuracy is just 6.66%. After I added CC12M with CC3M as training dataset, the top-5 evaluation accuracy raised to 23.76%. My tiny CLIP model checkpoint is here.
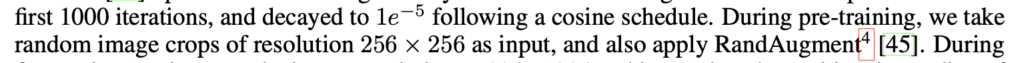







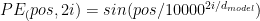
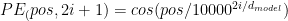
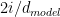 is 2. Therefore the smallest value in sin() is
is 2. Therefore the smallest value in sin() is  , which is very close to the minimal value of
, which is very close to the minimal value of