But they are different! As the source code show, the “encodeJpg()” use 100% quality and YUV444 chroma as default, but cv2 use 95% quality and YUV420 chroma as default.
If you want to write a JPEG file just as “encodeJpg()” do by using python, the code snippet should be:
import cv2
...
params = [cv2.IMWRITE_JPEG_QUALITY, 100, cv2.IMWRITE_JPEG_SAMPLING_FACTOR, cv2.IMWRITE_JPEG_SAMPLING_FACTOR_444]
success, encoded_image = cv2.imencode(".jpg", output_image, params)
if success:
with open(output_path, "wb") as fp:
fp.write(encoded_image)
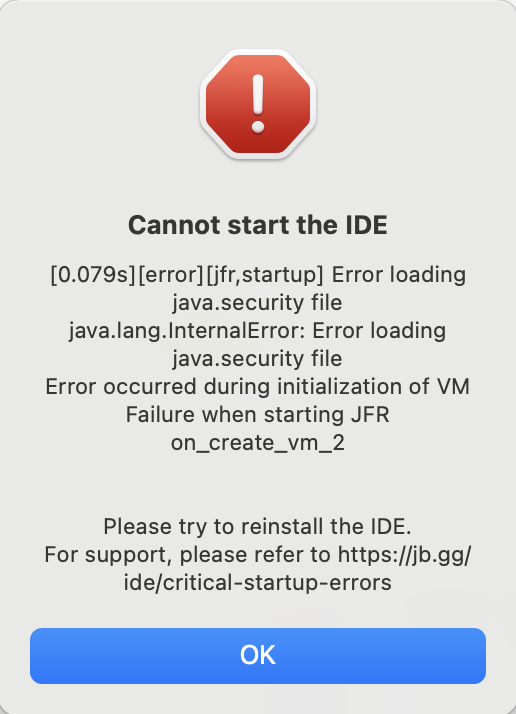
After I installed two versions of JDK (17 and 21) and uninstalled them, I saw this error when trying to launch my Android Studio. This error is hard to fix. Reinstalling Android Studio won’t fix it. And even after I searched google and asked chatGPT and try all the suggestion they give, the problem continued for two days.
The eventual solution is from a StackOverflow article (sorry I forget the url):
# firstly, manually uninstall Android Studio
# then
rm -rf /Library/Java/JavaVirtualMachines/*
# then
rm ~/Library/Application\ Support/Google/AndroidStudio*
# then
rm -rf ~/Library/Caches/
# now install the Android Studio and it could be launched correctly
This Python code runs with service account “XYZ” and we also want the schedule to run as service account “XYZ”. Make sense, right? But the execution throws errors:
grpc._channel._InactiveRpcError: <_InactiveRpcError of RPC that terminated with:
status = StatusCode.INVALID_ARGUMENT
details = "You do not have permission to act as service_account: vertex-runner@pers-decision-engine-dev.iam.gserviceaccount.com. (or it may not exist)."
debug_error_string = "UNKNOWN:Error received from peer ipv4:74.125.201.95:443 {created_time:"2024-06-06T01:51:02.837225888+00:00", grpc_status:3, grpc_message:"You do not have permission to act as service_account: vertex-runner@pers-decision-engine-dev.iam.gserviceaccount.com. (or it may not exist)."}"
Why does the Python Client of Vertex AI need to “act as” service account “XYZ” even if it’s already using default service account “XYZ”? I can’t answer. Fortunately, the solution is adding a role “Service Account User” to the service account “XYZ” (as this shows)
Seems Google Cloud still need to do a few works to let Vertex AI work very well.
After downloading the whole CC12M dataset from Huggingface, I wrote a tool to extract all of the image-text-pair files into one directory. But after extracting 17 million (17681010 exactly) files, the tool reported the error:
Exception: [Errno 28] No space left on device: '/home/robin/Downloads/cc12m/011647171.txt'
I checked the space and inodes in my ext4 filesystem, and seems they all have free capacity:
Seems the hash algorithm of “index_dir” of my ext4 filesystem is already “half_md4” therefore my only choice is using “tea”. (The default “hash_algo” when you using “mke2fs” is “half_md4“)
But after I make the change:
sudo tune2fs -E "hash_alg=tea" /dev/nvme0n1p1
the error “No space left on device” still jumped out…
There are two solutions left:
Rewrite my tool to generate flat big files with every file contains previous “small files”
Replace ext4 with xfs (I will test this after I got another NVME SSD)
After reading the classic paper about Skip-list, I tried to implement it by myself. But then I found a line of pseudo-code in the “Delete” function that I couldn’t understand:
Seems all the elements in “update” will point to “x”, so why do we need to check here? Maybe I can ignore this checking. Now here comes a part of my code:
def erase(self, num: int) -> bool:
update = Node(-1)
curr = self._head
for level in range(MAX_LEVEL-1, -1, -1):
while curr._forward[level] and curr._forward[level]._key < num:
curr = curr._forward[level]
update._forward[level] = curr
curr = curr._forward[0]
if curr == None or curr._key != num:
return False
curr._count -= 1
if curr._count > 0:
return True
for level in range(MAX_LEVEL):
update._forward[level]._forward[level] = curr._forward[level]
del curr
return True
But unfortunately, it failed for the test case. In the debugging process, I realized that not all elements in “update” will point to “x”. Le’ts just take the figure-1 from the paper as my example:
As above, imaging we are deleting node “17”. The “forward[1]” (index start from 0, this is the difference of my code with the paper) of node “9” is pointing to node “17” so it should be redirect to node “25”. But the “forward[3]” of node “6” is pointing to “NIL”, and shouldn’t be redirected to node “25” because “node6._forward[3]” didn’t point to node “17”. The situation is the same for “forward[4]” and beyond, of node “6”.
This is why the last few lines of my code should be:
......
for level in range(MAX_LEVEL):
if update._forward[level]._forward[level] != curr:
break
update._forward[level]._forward[level] = curr._forward[level]
del curr
return True
Just like the pseudo-code in the paper!
I am really respect to these academic guys — everytime I thought they were wrong is actually I missed something.
This paper introduced a method to extract only segments with bird sound from an audio file. Since the paper didn’t give any code, I started to write it by myself.
Here is the Python implementation:
import cv2
import time
import torch
import librosa
import soundfile as sf
import numpy as np
from torchlibrosa.stft import LogmelFilterBank, Spectrogram
class CFG:
n_fft = 2048
hop_length = 512
sample_rate = 32000
n_mels = 64
fmin = 150
fmax = 150000
class SignalExtractor:
def __init__(self):
self.spectrogram_extractor = Spectrogram(
n_fft=CFG.n_fft, hop_length=CFG.hop_length, win_length=CFG.n_fft, window="hann",
center=True, pad_mode="reflect", freeze_parameters=True)
# Logmel feature extractor
self.logmel_extractor = LogmelFilterBank(sr=CFG.sample_rate, n_fft=CFG.n_fft,
n_mels=CFG.n_mels, fmin=CFG.fmin, fmax=CFG.fmax, ref=1.0, amin=1e-10, top_db=None, freeze_parameters=True)
self.factors = [2.0, 1.8, 1.6, 1.4, 1.2, 1.1]
self.kernel_size = 15
self.sn_threshold = 0.2
def extract(self, input):
x = torch.from_numpy(input)
x = x[None, :].float()
x = self.spectrogram_extractor(x)
x = self.logmel_extractor(x)
x = x.squeeze(0).squeeze(0)
x = x.permute(1, 0).numpy()
x = x - np.amin(x)
for factor in self.factors:
sound, sn_ratio = self._factor_extract(input, x, factor)
if sn_ratio >= self.sn_threshold:
break
return sound, sn_ratio
def _factor_extract(self, input, x, factor: float):
rows, cols = x.shape
row_median = np.median(x, axis=1)
row_median_matrix = np.tile(row_median, (cols, 1)).T * factor
col_median = np.median(x, axis=0)
col_median_matrix = np.tile(col_median, (rows, 1)) * factor
y = x > row_median_matrix
z = x > col_median_matrix
res = np.logical_and(y, z) + np.zeros(x.shape)
kernel = np.ones((self.kernel_size, self.kernel_size), np.uint8)
img = cv2.dilate(res, kernel, iterations=1)
indicator = np.sum(img, axis=0)
chunk_size = input.shape[0] // indicator.shape[0]
sounds = []
for index, chunk in enumerate(indicator):
if chunk > 0:
sounds.append(input[index*chunk_size:(index+1)*chunk_size])
if len(sounds) <= 0:
return None, 0.0
sound = np.concatenate(sounds)
return sound, sound.shape[0]/input.shape[0]
The implementation has some differences from the method in the paper:
I didn’t use erosion since dilation is good enough for picking up the bird-sound segment
three times bigger than median is too strict for most audio files, so I use an array of ratios. When the 2.0 ratio couldn’t pick up any bird sound, the code will automatically try a 1.8 ratio etc.
I used a big kernel (15, 15) for dilation since it works well in my samples
Traceback (most recent call last):
File "reviewjpgs_optimaztion_testing.py", line 27, in <module>
import intel_extension_for_pytorch as ipex
File "/home/hero/.pyenv/versions/3.8.12/lib/python3.8/site-packages/intel_extension_for_pytorch/__init__.py", line 11, in <module>
from .cpu import _cpu_isa
File "/home/hero/.pyenv/versions/3.8.12/lib/python3.8/site-packages/intel_extension_for_pytorch/cpu/__init__.py", line 1, in <module>
from . import runtime
File "/home/hero/.pyenv/versions/3.8.12/lib/python3.8/site-packages/intel_extension_for_pytorch/cpu/runtime/__init__.py", line 3, in <module>
from .multi_stream import MultiStreamModule, get_default_num_streams, \
File "/home/hero/.pyenv/versions/3.8.12/lib/python3.8/site-packages/intel_extension_for_pytorch/cpu/runtime/multi_stream.py", line 4, in <module>
import intel_extension_for_pytorch._C as core
ImportError: /home/hero/.pyenv/versions/3.8.12/lib/python3.8/site-packages/intel_extension_for_pytorch/lib/libintel-ext-pt-cpu.so: undefined symbol: _ZNK3c1010TensorImpl22is_strides_like_customENS_12MemoryFormatE
The answer is quite tricky: need to install the IPEX package with the same version of PyTorch.
After the testing of both torch.jit.trace and this IPEX, we found out that `torch.jit.trace` could boost the performance of prediction significantly but IPEX could not.
I want my Python script to receive one message from a PubSub topic and then go on to other work. The code is learned from an example of the GCP document:
with subscriber:
# The subscriber pulls a specific number of messages. The actual
# number of messages pulled may be smaller than max_messages.
response = subscriber.pull(
request={"subscription": subscription_path, "max_messages": NUM_MESSAGES},
retry=retry.Retry(deadline=300),
)
if len(response.received_messages) == 0:
return
The problem is that it will receive empty messages, meaning that “len(response.received_messages)” is zero.
Where do these empty messages come from? Here is the answer:
Once a message is sent to a subscriber, the subscriber must either acknowledge or drop the message. A message is considered outstanding once it has been sent out for delivery and before a subscriber acknowledges it.
My solution is just to wait until receiving a non-empty message:
with subscriber:
# The subscriber pulls a specific number of messages. The actual
# number of messages pulled may be smaller than max_messages.
while True:
response = subscriber.pull(
request={"subscription": subscription_path, "max_messages": NUM_MESSAGES},
retry=retry.Retry(deadline=300),
)
if len(response.received_messages) > 0:
break