After training both image classification and sound classification deep learning models. I found out that the image training is much slower than the sound training, although the sound dataset is much bigger than image dataset.
The first idea that jumped out of my mind is that the image has 3 channels (RGB) but the sound spectrogram just have 1 channel. Therefore if I compress RGB into 1 channel (such as using gray image), the training speed of image classification will become 3 times faster.
A few days ago, I started to train the image classification with gray image. But the speed of training is almost the same with RGB image. Until then, I realized how stupid I am.
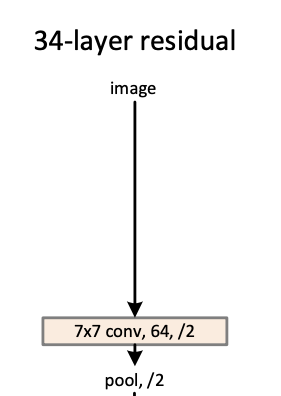
Let’s see below graph cut from residual network paper. Yes, the first layer is a 7×7 64 filters convoluation, and it will map no matter how many channels just to 64 filters. If the image is a gray one, it maps it to 64 filters; if the image is a RGB one, it also maps it to 64 filters. The computing cost will only reduce 3 times for first layer if I reduce the 3-channels to 1-channel. Compare to total computing cost, this change is quite minor.
That’s why there is no body mentioned about this “accelerating” technology before 🙂