Bayesian Optimization is a popular searching algorithm for hyper-parameters in the machine learning area.
There are also two popular Python libraries for this algorithm: Hyperopt and Optuna. So I have done some experiments on these two libraries. The trial is using LightGBM to classify tabular data, and the hyper-parameters and their ranges are:
- n_estimators (10~100000)
- learning_rate (0.0001~1.0)
- num_leaves (2, 2000)
- max_depth (2, 200)
- min_child_samples (1, 10000)
- reg_alpha (0.001, 10.0)
- reg_lambda (0.001, 10.0)
I run 10 trials each time for 10 times, by using different algorithms in Hyperopt and Optuna. The result for Hyperopt is:
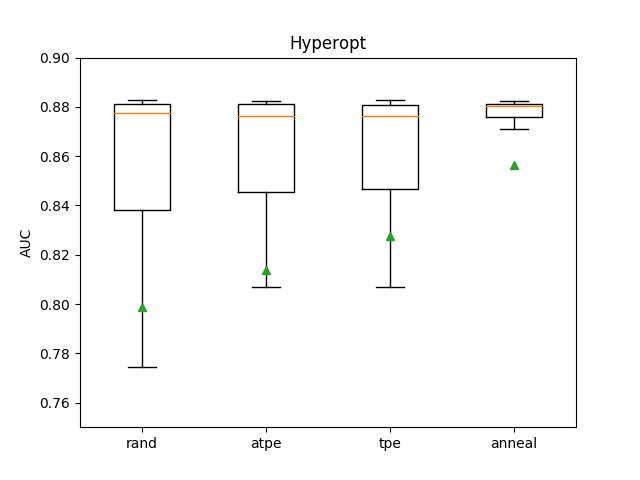
And the result for Optuna is:
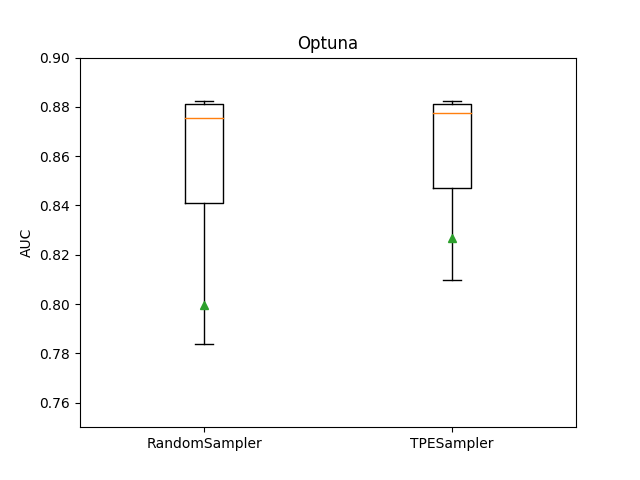
Seems that for my tabular data, TPE and Annealing works best, and Hyperopt works better than Optuna