As the above menu show in the Vertex AI, it is trying to include all common processes of building and running a machine learning model.
For my experiment, I just create a Dataset by loading file from GCS. Unfortunately, the loading process support only CSV file as tabular data so I have to convert my big PARQUET file into CSV format first (really inconvenient).
- Strange error
But after I created a training process by using builtin XGBoost container. It report a strange error:
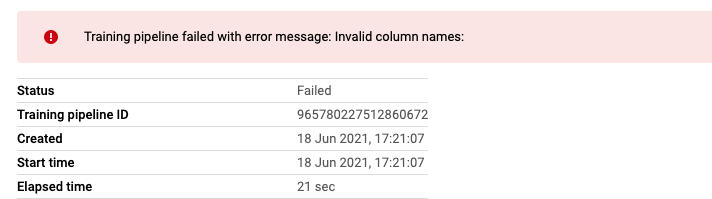
There is an invalid column, but what’s the name of it? The GUI didn’t show. I finally find out that it’s a column with an empty name. Seems Vertex AI couldn’t even process a table with a column of an empty name.
2. AutoML
After manually removed the column with an empty name and select AutoML for my tabular data. The training went successfully. The final regression L1 loss is 0.237, just the same result with my own LightGBM model.
3. Custom Pakcage
By following this document, I create a custom Python package for my training of the XGBoost model. The self-brew package use environment-variable to get Dataset from GCS. The final L1 loss is slightly worse than LightGBM.
Frankly speaking, I haven’t seen any advantage of Vertex AI over our home-brew Argo/K8S training framework. In the Vertex AI training process, those special errors, like OOM(Out Of Memory), are hard to discover.