Previously, I was using CUB-200 dataset to train my object detection model. But after I used CUB-200-2011 dataset instead, the training loss became ‘nan’.
iter 10 || Loss: 17.9996 || timer: 0.2171 sec. iter 20 || Loss: nan || timer: 0.2145 sec. iter 30 || Loss: nan || timer: 0.2145 sec. ...
I tried to reduce the learning rate, change optimizer from SGD to Adam, and use different types of initializer for parameters. None of these solved the problem. Then I realized it would be a hard job to find the cause of the problem. Thus I began to print the value of ‘loss’, then the values of ‘loss_location’ and ‘loss_confidence’. Finally, I noticed that ‘loss_location’ firstly became ‘nan’ because of the value of 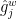

‘loss_location’ from paper ‘SSD: Single Shot MultiBox Detector’
After checked the implementation in the ‘layers/box_utils.py’ of code:
def encode(matched, priors, variances):
...
# dist b/t match center and prior's center
g_cxcy = (matched[:, :2] + matched[:, 2:])/2 - priors[:, :2]
# encode variance
g_cxcy /= (variances[0] * priors[:, 2:])
# match wh / prior wh
g_wh = (matched[:, 2:] - matched[:, :2]) / priors[:, 2:]
g_wh = torch.log(g_wh) / variances[1]
# return target for smooth_l1_loss
return torch.cat([g_cxcy, g_wh], 1) # [num_priors,4]
I realized the (matched[:, 2:] – matched[:, :2]) has got a negative value which never happend when using CUB-200 dataset.
Now it’s time to carefully check the data pipeline for CUB-200-2011 dataset. I reviewed the bounding box file line by line and found out that the format of it is not (Xmin, Ymin, Xmax, Ymax), but (Xmin, Ymin, Width, Height)! Let’s show the images for an incorrect bounding box and correct one:

Parse bounding box by format (Xmin, Ymin, Xmax, Ymax) which is wrong

Parse bounding box by format (Xmin, Ymin, Width, Height) which is correct
After changed the parsing method for the bounding boxes of CUB-200-2011 dataset, my training process runs successfully at last.
The lesson I learned from this problem is that dataset should be seriously reviewed before using.