Imaing we have data like this:
WITH Sequences AS (SELECT 1 AS id, [0, 1, 1, 2, 3, 5] AS prod_type, [1.1, 1.2, 2.1, 2.3, 3.3, 3.4] AS prod_price, UNION ALL SELECT 2 AS id, [2, 4, 8, 16, 32] AS prod_type, [1.3, 4.2, 2.1, 7.3, 5.3, 9.4] AS prod_price, UNION ALL SELECT 3 AS id, [5, 10] AS prod_type, [1.8, 4.9, 2.0, 7.6, 5.1, 8.4] AS prod_price) select * from sequences
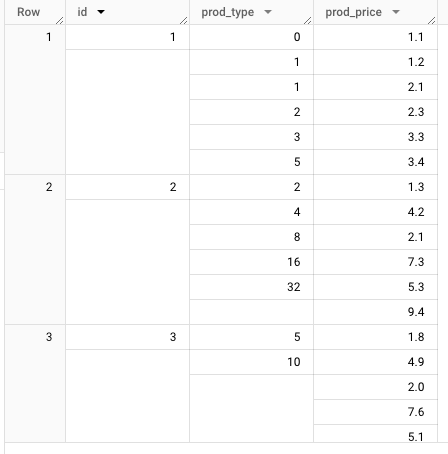
How could I get the total price of each “prod_type” for every “id”?
First we need to unfold the “prod_type” and “prod_price” correspondingly:
WITH Sequences AS (SELECT 1 AS id, [0, 1, 1, 2, 3, 5] AS prod_type, [1.1, 1.2, 2.1, 2.3, 3.3, 3.4] AS prod_price, UNION ALL SELECT 2 AS id, [2, 4, 8, 16, 32] AS prod_type, [1.3, 4.2, 2.1, 7.3, 5.3, 9.4] AS prod_price, UNION ALL SELECT 3 AS id, [5, 10] AS prod_type, [1.8, 4.9, 2.0, 7.6, 5.1, 8.4] AS prod_price) SELECT id, prod_type, prod_price from sequences, unnest(prod_type) AS prod_type, unnest(prod_price) AS prod_price;
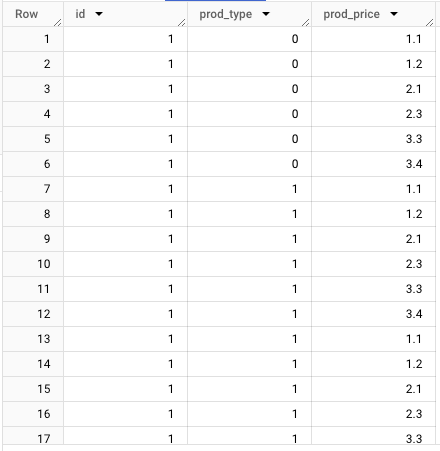
and then use “group by” to calculate total price:
... SELECT id, prod_type, SUM(prod_price) FROM sequences, UNNEST(prod_type) AS prod_type, UNNEST(prod_price) AS prod_price GROUP BY id, prod_type