In Tensorflow, we could use Optimizer to train model:
train_op = optimizer.minimize(loss, global_step=global_step)
....
sess.run([train_op], feed_dict={x: batch[0], y_: batch[1]})
But sometimes, model need to be split to two parts and trained separately, so we need to compute gradients and apply them by two steps:
first_part_vars = []
second_part_vars = []
for var in tf.trainable_variables():
if var.name.find("first_part/") >= 0:
first_part_vars.append(var)
if var.name.find("second_part/") >= 0:
second_part_vars.append(var)
....
first_grads_and_vars = opt.compute_gradients(loss, var_list = first_part_vars)
train_first_part_op = opt.apply_gradients(first_grads_and_vars)
second_grads_and_vars = opt.compute_gradients(loss, var_list = second_part_vars)
train_second_part_op = opt.apply_gradients(second_grads_and_vars)
....
Then how could we delivery gradients from first part to second part? Here is the equation to answer:
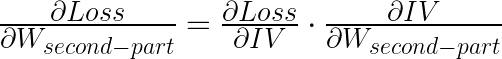
The
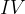 means ‘intermediate vector’, which is the interface vector between first-part and second-part and it is belong to both first-part and second-part. The
means ‘intermediate vector’, which is the interface vector between first-part and second-part and it is belong to both first-part and second-part. The 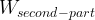 is the weights of second part of model. Therefore we could use tf.gradients() to connect gradients of two parts:
is the weights of second part of model. Therefore we could use tf.gradients() to connect gradients of two parts:
first_grads_and_vars = opt.compute_gradients(loss, var_list=[first_part_vars.extend(iv)])
train_first_part_op = opt.apply_gradients(first_grads_and_vars)
iv_ph = tf.placeholder(tf.float32, iv.shape)
second_grads = tf.gradients(loss, second_part_vars, iv_ph)
second_grads_and_vars = list(zip(second_grads, second_part_vars))
train_second_part_op = opt.apply_gradients(second_grads_and_vars)
....
_, ivg = sess.run([train_first_part_op, iv_gradients], feed_dict = {x: batch[0], y_: batch[1]})
sess.run([train_second_part_op], feed_dict = {x: batch[0], iv_ph: ivg})