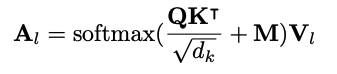Instead of using other strange components of Kubeflow, we can just use Kubeflow Pipelines which is much easier to be deployed and used.
After deployment (less than 20 minutes), I test my first example and it succeeded:
import kfp
from kfp.components import func_to_container_op, InputPath, OutputPath
@func_to_container_op
def do_something(output_csv: OutputPath(str)):
with open(output_csv, "w") as writer:
writer.write("name,score\n")
writer.write("hello,100\n")
writer.write("world,50\n")
@func_to_container_op
def show_something(input_csv: InputPath()):
with open(input_csv, "r") as reader:
for line in reader:
print(line)
def do_and_show_something():
csv_data = do_something()
csv_data.set_memory_limit("1G")
csv_data.set_cpu_limit("0.5")
show_op = show_something(csv_data.output)
show_op.set_memory_limit("1G")
show_op.set_cpu_limit("0.5")
if __name__ == "__main__":
kfp.compiler.Compiler().compile(do_and_show_something, __file__ + ".yaml")To limit the resource (CPU/Memory), we only need to call the function of the op (Operation).
Then python3 xxx.py to convert the python script file to YAML, and upload the YAML file to Kubeflow Pipelines.
That is how easy to use just Pipeline component of Kubeflow!